Attention: The room location of
the talks has changed due to the increase in registrations, see below for
directions.
Also the accepted posters are available
below.
We are happy to announce the inaugural New York Metro Database/Information
Retrieval (DB/IR) Day. We hope that this is the first in a regular series
of New York Metro DB/IR Days.
The New York Metro DB/IR Day will bring together database and
information retrieval researchers and students from academic and research institutions
across the Greater New York area for an exciting workshop technical program as well
as informal discussion. The DB/IR workshops will provide a regular forum for presenting
diverse viewpoints on database systems and information retrieval, addressing current
topics as well as promoting information exchange among researchers.
The first DB/IR Day will be hosted by
Columbia University on April 15, 2005. The
program will consist of three technical keynote lectures from
distinguished researchers in databases and information retrieval (Alon
Halevy, Craig Nevill-Manning and Michael Stonebraker). In addition,
we are organizing a student poster session to promote awareness of current DB&IR
research at various graduate departments in the North-East area, and stimulate collaborations
between academia and industry. Prizes will be awarded for the best posters!
DB/IR Day will conclude in time for everyone to enjoy an evening
in New York City.
Here is the first DB/IR day exciting agenda:
|
|
|
|
Date:
|
Friday, April
15, 2005
|
|
Time:
|
11:00AM
to 5:00PM (approx).
|
|
Place:
|
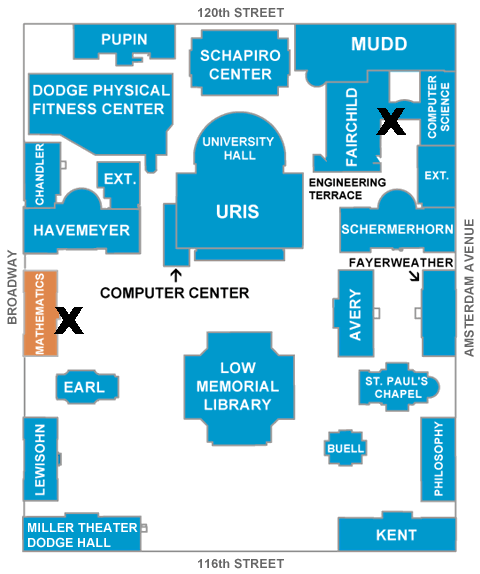
1214 Amsterdam Avenue
New York, NY 10027
The day will take place in the
Mudd Engineering Building
(Click here for
directions)
and in the Mathematics Building
(Click here for the map). Both buildings
are very close to each other.
|
|
Agenda:
|
| 10:30AM
– 11:00AM 207
Mathematics |
Registration
|
|
11:00AM – 11:10AM
207
Mathematics |
Welcome
|
| 11:10AM
– 12:30PM 207
Mathematics |
Semex:
a Platform for Personal Information Management and Integration
Alon Halevy, Computer Science and
Engineering Department, University of Washington
Abstract
The explosion of information available in digital form has made search
a hot research topic for the Information Management Community. While most
of the research on search is focused on the WWW, individual computer users
have developed their own vast collections of data on their desktops, and
these collections are in critical need for good search and query tools.
The problem is exacerbated by the proliferation of varied electronic devices
(laptops, PDAs, cellphones) that are at our disposal, that often hold
subsets or variations of our data.
I will argue that Personal Information Management (PIM) poses a key
challenge to our community and raises several exciting technical problems.
In particular, PIM highlights some of the challenges involved in combining
data management and information retrieval technologies.
I will demonstrate the vision of PIM and the associated problems with
the Semex System that we are building at the University of Washington.
Semex has two main goals. The first goal is to enable browsing and searching
personal information by semantically meaningful associations, in the spirit
of the Memex vision. The challenge to enabling such browsing and search
is to automatically create such associations between data items on one's
desktop, and to create enough of them so Semex becomes an indispensable
tool. Our second goal is to leverage the personal information space we
created to increase users' productivity. As our first target, Semex leverages
the personal information to enable lightweight information integration
tasks that are discouragingly difficult to perform with today's tools.
This is joint work with Luna Dong and Jayant Madhavan.
|
| 12:30PM
– 01:00PM |
LUNCH |
| 01:00PM
– 02:20PM 207
Mathematics |
Neither fish nor
fowl - between relations and bags of words Craig
Nevill-Manning, Director, New York Engineering & Senior Staff Research
Scientist, Google Inc.
Abstract
Search engines like Google help users to sift unstructured
documents, treating them largely as bags of words. Relational
databases allow retrieval using complex, precise queries. But there's
a large amount of data that falls between the two extremes --
databases that are presented as documents (e.g. an Amazon product
page), and documents that contain structured data (e.g. the address
and phone number on your home page.) This information is not
sufficiently structured to permit relational indexing and searching,
but treating it as a bag of words loses valuable information.
Furthermore, it's difficult to design schemas for everything in the
world, so a relational model is too restrictive. Google is currently
wrestling with these issues: Froogle uses dynamic programming to
extract structured information about products, and allows users to
query products on various attributes.
Google Local scours the web for geographical references, and
combines these with structured data from yellow pages. Google Scholar
reconstructs a citation graph by extracting title and author
information from the first page and references of academic
publications. I'll give some background on these problems, describe
the way we approach them at Google, and discuss the impact that
solutions will have on the way people access and use information.
|
| 02:20PM
– 03:40PM
CS Conference Room
4th Floor Mudd |
Student Posters and Coffee
Break
Students are encouraged
to present their work during the afternoon poster session
We are inviting poster abstract
submissions (around 250 words) due no later than March 31st.
Please send poster abstracts to Ioana Stanoi (irs@us.ibm.com)
or George Mihaila (mihaila@us.ibm.com).
Accepted Posters
|
| 03:40PM
– 05:00PM 207
Mathematics |
One Size
Fits All: An Idea Whose Time Has Come and Gone
Michael Stonebraker, Computer Science
and Artificial Intelligence Laboratory, M.I.T., and StreamBase Systems,
Inc.
Abstract
The last 25 years of commercial DBMS development can be summed up in
a single phrase: One size fits all. This phrase refers to the fact that
the traditional DBMS architecture (originally designed and optimized for
business data processing) has been used to support many data-centric applications
with widely varying characteristics and requirements.
In this talk, we argue that this concept is no longer applicable to
the database market, and that the commercial world will fracture into
a collection of independent database engines, some of which may be unified
by a common front-end parser. We use examples from the stream-processing
market and the data-warehouse market to bolster our claims. We also briefly
discuss other markets for which the traditional architecture is a poor
fit and argue for a critical rethinking of the current factoring of systems
services into products.
|
|
|
DB/IR day T-shirt and a lunch box will be available for those
who register. To register, please fill out the form below if you are planning
to join us. We will only use your email to send you invitation to future
DB/IR Day events:
New York Metro DB/IR Day Organization Committee:
|
|
|
|
Workshop Chairs:
|
|
|
Assistant Chairs:
|
|
|
Local Arrangements:
|
|
|

{kind=link}
{kind=link}